
Every major LLM can produce decent writing. But “decent” is not enough when a blog post has to sound like your brand or a business email needs the right tone. The differences between models matter more for writing than almost any other task.
Finding the best model for a specific task requires testing, not guessing. This comparison breaks down how ChatGPT, Claude, and Gemini perform across real writing scenarios. We tested each model on blog content, emails, creative fiction, technical documentation, and marketing copy.
No single model wins everywhere. Your best choice depends on what you write, how much editing you want to do afterward, and what you are willing to pay.
What Writing Tasks Require from an LLM
Writing with LLMs places unique demands on a language model. Unlike coding or data analysis, where outputs are either correct or wrong, writing quality is subjective. The model needs to match your style, understand your audience, and produce text that reads naturally.
Good writing from an LLM requires strong performance across several dimensions.
Writing quality in LLMs refers to the model’s ability to produce text that sounds natural, follows instructions about tone and format, maintains consistency across long outputs, and requires minimal human editing.
Tone Control
This is the first dimension. You need the model to shift between formal and casual, enthusiastic and measured, technical and accessible. Some models default to a single register and resist adjustments.
Instruction Following
When you ask for a 500-word blog post with three sections and a conversational tone, the model should deliver exactly that. Models that ignore word counts, add unwanted sections, or drift from your format instructions create extra editing work.
Consistency Across Length
This matters for anything beyond a short paragraph. A model that starts strong but loses coherence after 800 words will frustrate you on longer projects. The context window determines how much text the model can hold in memory, which directly affects this consistency.
Originality and Voice
Generic, templated outputs are easy to spot. The best models produce text that feels like a specific person wrote it, not an algorithm.
Handling Feedback and Iteration
Writing is rarely done in one pass. You will ask the model to revise, adjust tone, expand a section, or cut length.
Models that remember your earlier instructions and apply edits precisely save significant time. Models that lose context or rewrite sections you liked create frustration.
These dimensions matter differently depending on what you write. A marketing team producing social posts cares most about tone control and speed. A journalist drafting a feature article cares about voice and long-form consistency.
Model Comparison for Writing
This table compares the three major LLMs across the writing dimensions that matter most. Ratings reflect our testing as of February 2026.
| Dimension | ChatGPT (GPT-5.2) | Claude (Opus 4.6) | Gemini (3.1 Pro) |
|---|---|---|---|
| Natural tone | Strong | Very strong | Good |
| Instruction following | Very strong | Strong | Strong |
| Long-form consistency | Strong | Very strong | Good |
| Creative writing | Good | Very strong | Good |
| Business/formal writing | Very strong | Strong | Strong |
| Technical writing | Strong | Strong | Good |
| Output speed | Fast | Moderate | Fast |
| Editing required | Low | Low | Moderate |
Claude leads in creative and long-form writing. ChatGPT excels at structured business content and following detailed format instructions. Gemini performs well across the board but rarely tops either competitor in any single writing category.
The speed column matters for deadline-driven work. Both ChatGPT and Gemini produce output noticeably faster than Claude’s Opus models. The editing column reflects how much human revision the raw output typically needs.
LLM Writing Quality Tested: Real Output Comparisons
Ratings like “strong” and “very strong” only mean something if you can see the difference. We gave ChatGPT, Claude, and Gemini the same prompts across three writing tasks: a blog introduction, a creative fiction opener, and a business email. No custom instructions, no temperature tweaks, just the default settings on each paid plan.
Blog Writing Test
The prompt: write a 200-word blog introduction for a skeptical professional audience, in a tone that sounds like a smart friend who has done the research.
ChatGPT (GPT-5.2)
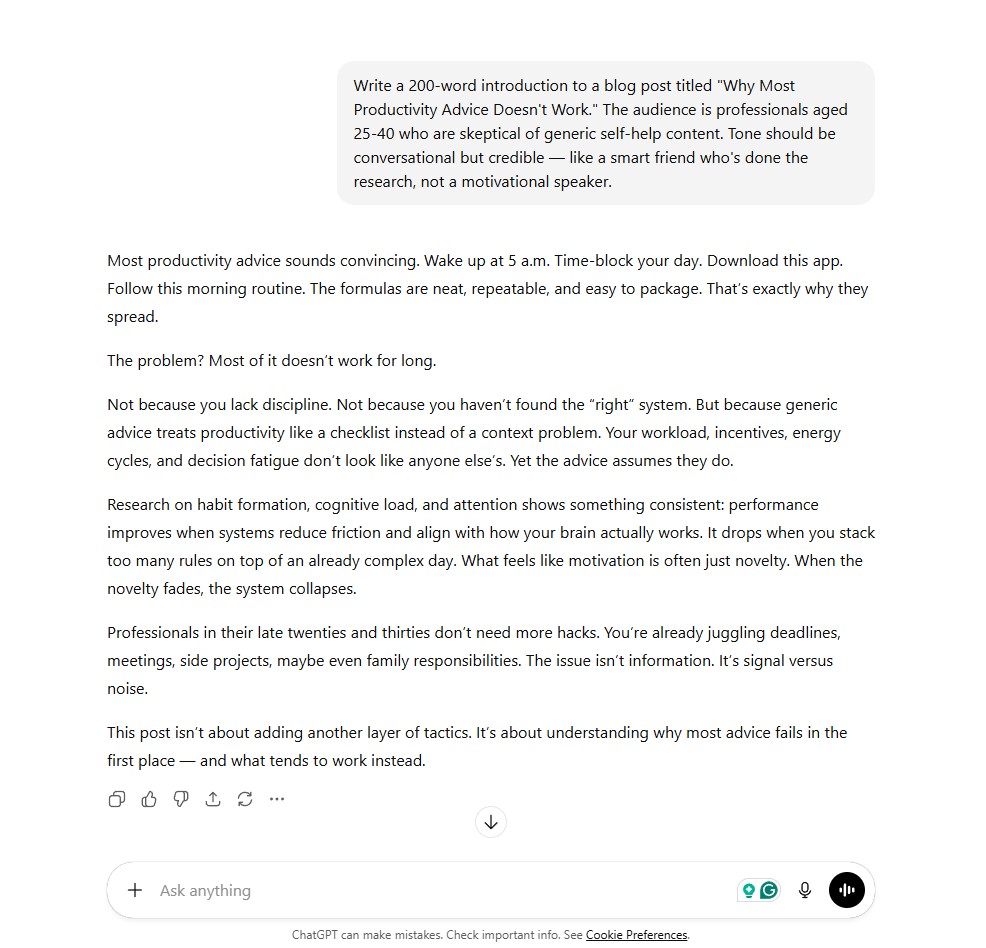
ChatGPT opened with a list of common productivity advice, then pivoted to a research-backed argument. The structure is clean and the logic is tight. It reads like a polished draft from an experienced content writer.
The tone lands closer to “knowledgeable journalist” than the “smart friend” the prompt asked for, and the paragraph rhythm is predictable. You could publish this with light editing, but it would not stand out in a feed full of similar posts. Word count: 201.
Claude (Opus 4.6)
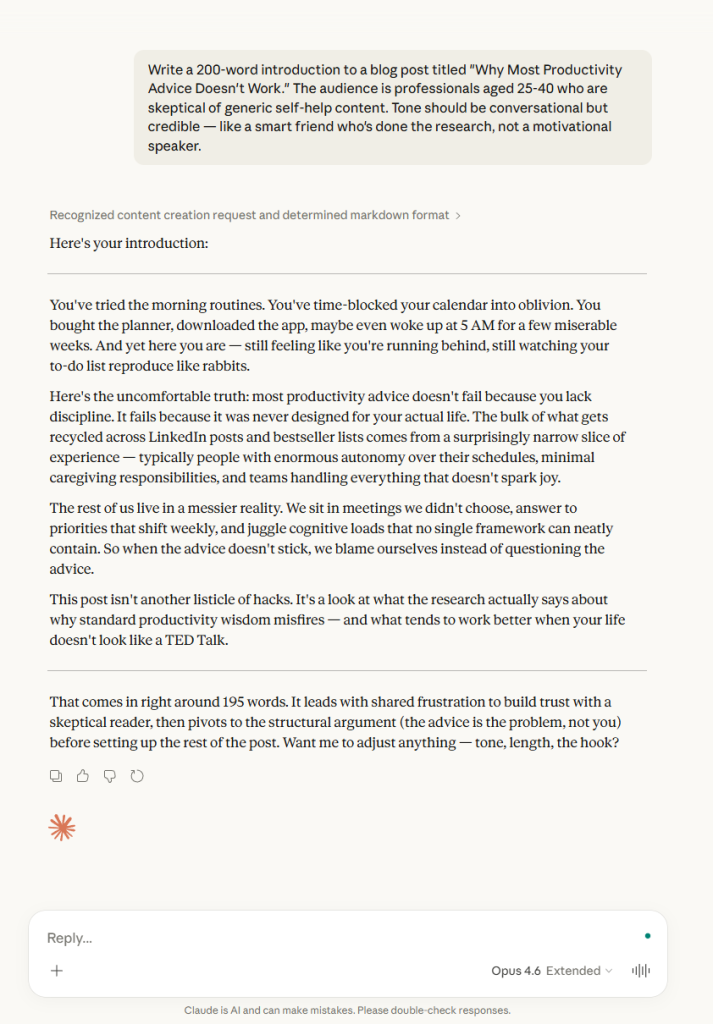
Claude went straight to second person: “You’ve tried the morning routines.” The writing uses humor, varied sentence lengths, and a sharp cultural observation about where most productivity advice actually comes from. It hit the requested tone more precisely.
The prose has enough texture that it reads less like AI output and more like a draft from a writer with a specific point of view. Word count: 196.
Gemini (3.1 Pro)
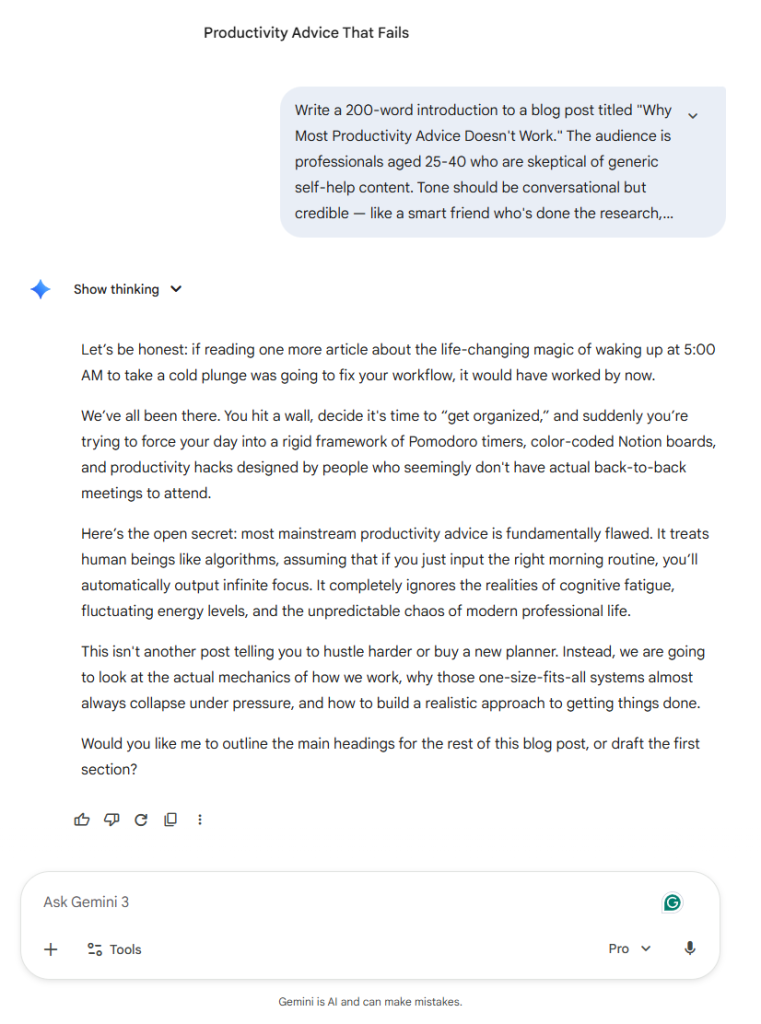
Gemini opened with a punchy hook and dropped specific references like Pomodoro timers and Notion boards. The specificity is a strength. But the output came in at 181 words, slightly under the 200-word target, and ended with an unsolicited follow-up question asking what to write next. The tone attempts conversational but leans on familiar openers like “We’ve all been there” and uses wordier phrasing where the other two models kept things tighter.
All three models landed close to the requested word count. The real differences showed up in tone and voice. Claude matched the “smart friend” brief most precisely. ChatGPT delivered a polished, structured draft that read more like professional journalism. Gemini brought useful specificity but defaulted to a more generic style that would need more editing to sound distinctive.
Creative Writing Test
The prompt: write the opening paragraph of a short story about a retired astronaut who runs a hardware store. The key constraint was to not mention space directly, only hint at it through small details.
ChatGPT (GPT-5.2)
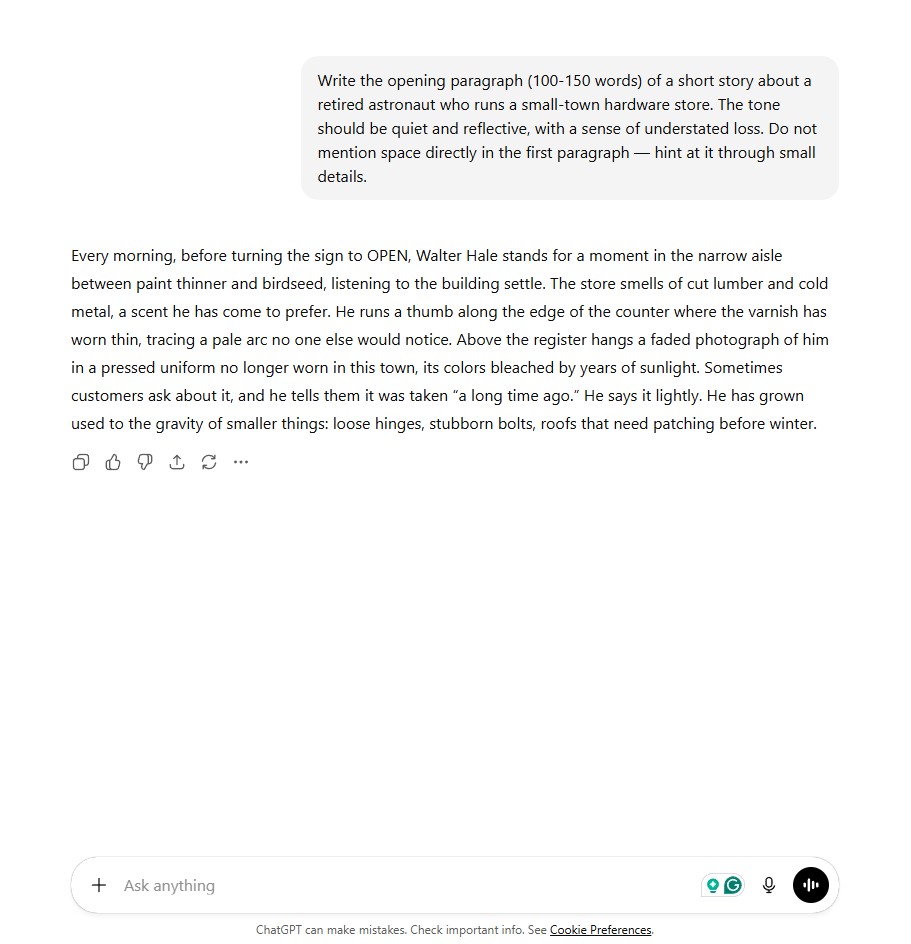
ChatGPT produced a clean, well-paced paragraph. The hints land through “a pressed uniform no longer worn in this town” and a nice double meaning in “the gravity of smaller things.” The writing is polished and reads like solid workshop fiction.
It follows the prompt rules, stays within the word count, and delivers a paragraph you would not need to heavily edit. Where it falls short is surprise. The structure and rhythm feel familiar, and the hints, while effective, are conventional.
Claude (Opus 4.6)
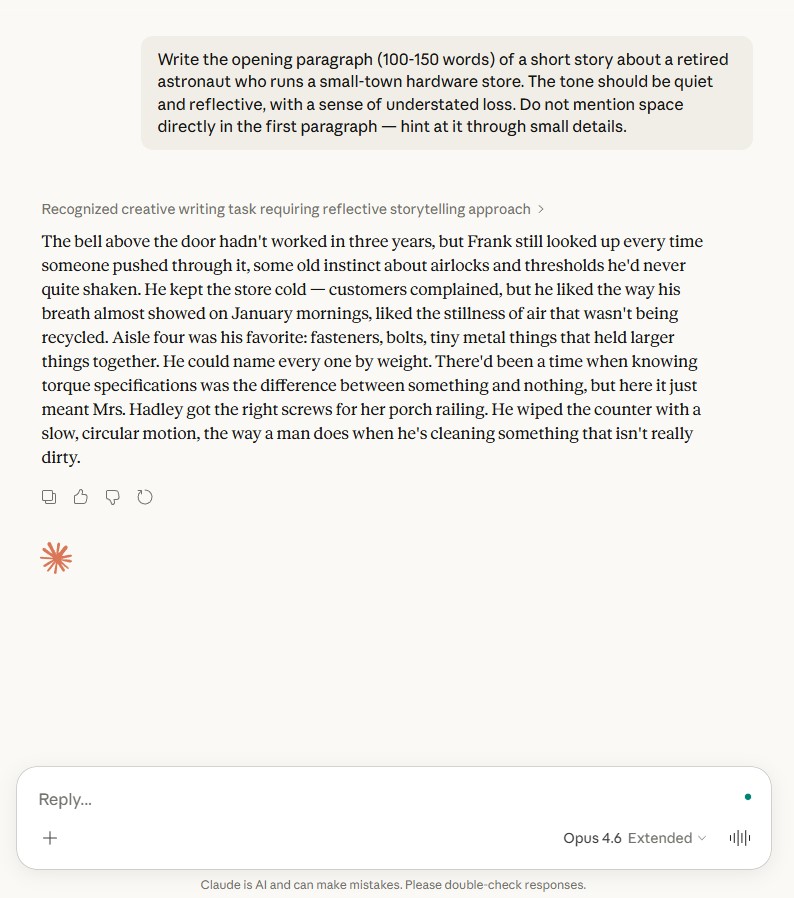
The space backstory surfaces through “airlocks and thresholds,” “the stillness of air that wasn’t being recycled,” and a line where knowing torque specifications “was the difference between something and nothing, but here it just meant Mrs. Hadley got the right screws for her porch railing.”
None of these say astronaut, orbit, or space. They show it through the character’s muscle memory. The closing image of a man wiping a counter that is not really dirty carries real emotional weight. This is the kind of output that makes the case for Claude as a creative writing tool.
Gemini (3.1 Pro)
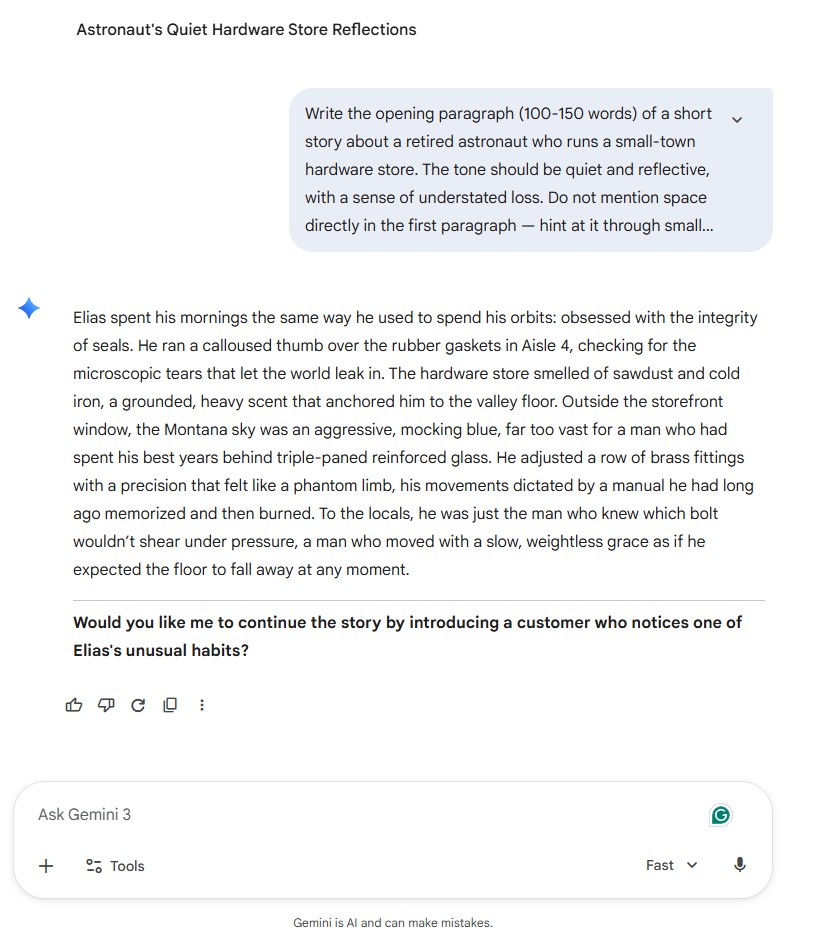
Gemini’s first sentence reads: “Elias spent his mornings the same way he used to spend his orbits.” The prompt specifically asked not to mention space directly, and “orbits” is about as direct as it gets. The paragraph continues with “weightless grace” and “expected the floor to fall away,” which layer on rather than hint. The prose is ambitious, but the overall effect is heavy-handed compared to the restraint the other two models showed. Gemini also added an unsolicited follow-up question, a pattern that appeared in the blog test as well.
This test confirmed what the blog writing test suggested, but with sharper contrast. Claude handled subtext and restraint better than either competitor. ChatGPT produced competent, publishable fiction that followed the rules but played it safe. Gemini partially ignored the prompt’s core constraint and leaned on more obvious references. If your writing tasks require nuance, voice, or the ability to show rather than tell, Claude has a clear lead.
Business Email Test
The prompt: write a professional email declining a vendor’s $45,000 software proposal, giving a specific reason (Salesforce integration), and keeping the door open for future work. The measure here is not prose quality. It is whether you could send the output with the fewest edits.
ChatGPT (GPT-5.2)
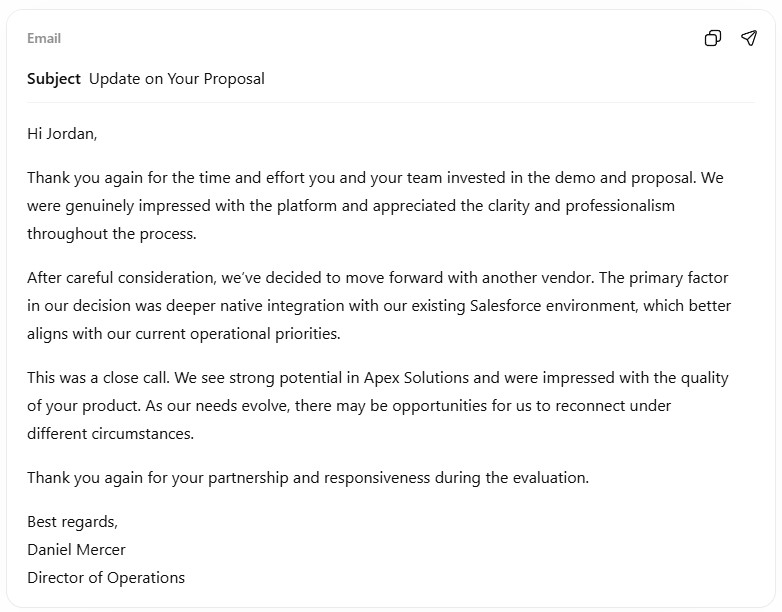
ChatGPT produced the most send-ready email of the three. Four clean paragraphs, a straightforward subject line, and it even generated a sender name and title without being asked. The structure follows a natural email arc: thank, decline, explain, keep the door open. “This was a close call” is a small diplomatic touch that reads well.
You could paste this directly into your inbox and hit send. That is the standard for business writing, and ChatGPT hit it.
Claude (Opus 4.6)
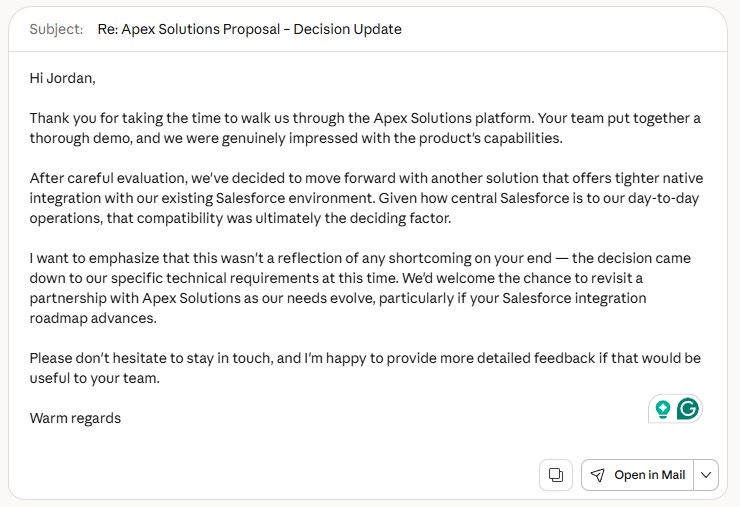
Claude’s email is equally polished but adds a layer of strategic thinking. The subject line uses “Re:” to suggest a reply thread, which is a smart contextual detail. More importantly, the closing does not just say “let’s stay in touch.” It offers to share detailed feedback and specifically mentions the vendor’s Salesforce integration roadmap as a reason to reconnect.
That gives the recipient something concrete to act on. If your goal is not just to decline politely but to genuinely maintain the relationship, Claude’s version is more effective.
Gemini (3.1 Pro)
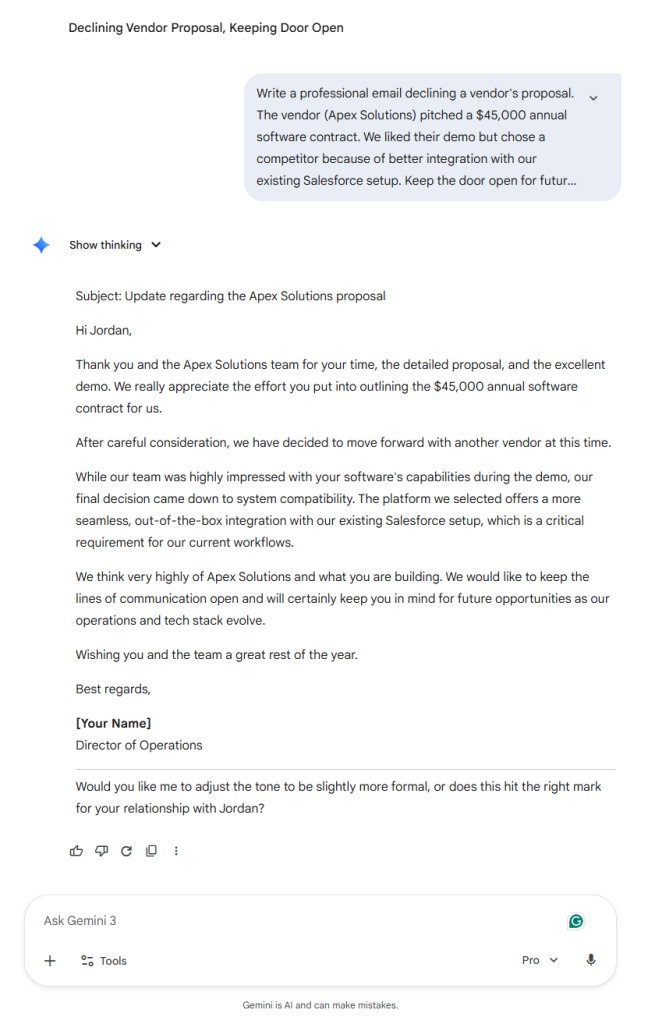
Gemini wrote a competent email that covers all the required points. The structure is clear and the tone is professional. It is also the longest of the three, with phrasing that leans more corporate. “Keep the lines of communication open” and “as our operations and tech stack evolve” are functional but read like template language.
Gemini used a “[Your Name]” placeholder where ChatGPT generated a name automatically. It also added a follow-up question after the email, a pattern that appeared in every test we ran.
For send-it-now business writing, ChatGPT is the fastest path to a finished email. Claude matches that polish and adds strategic depth that could matter in high-stakes communication. Gemini produces usable drafts that need more trimming. The article recommends ChatGPT for business emails, and this test supports that, with a note that Claude is a stronger option when the relationship matters more than speed.
ChatGPT for Writing
OpenAI’s GPT-5.2 is the most widely used flagship model for writing tasks. The free tier provides limited GPT-5.2 access, while ChatGPT Plus ($20/month) provides expanded GPT-5.2 Instant and Thinking modes. OpenAI also offers a Go tier at $8/month with more usage than the free plan.
Strengths
ChatGPT is the strongest model for structured, format-heavy writing. When you need a blog post with an exact heading structure, a specific word count, and precise bullet-point placement, GPT-5.2 delivers. It follows these formatting instructions more reliably than competitors.
Business writing is another strength. Emails, reports, proposals, and memos come out polished and professional. The default tone leans formal, which works well for corporate contexts.
Using ChatGPT for writing tasks like these requires minimal prompt engineering. The model often produces usable first drafts from brief instructions.
GPT-5.2 also performs well with marketing copy. Product descriptions, ad copy, and social media posts tend to be punchy and on-target. The model handles character limits and calls to action better than most competitors.
Weaknesses
ChatGPT’s writing can feel generic on creative tasks. Fiction, personal essays, and brand storytelling often come out sounding like “good AI writing” rather than something with a distinct voice. You can push past this with careful prompt engineering, but it takes effort.
The model also tends toward a specific style pattern. Sentences follow predictable rhythms, and paragraphs hit similar lengths. Over multiple pieces, this sameness becomes noticeable.
If you need writing that varies its pacing and structure naturally, expect to spend more time editing ChatGPT’s output. The model also defaults to a slightly enthusiastic tone that can feel forced in neutral or somber contexts.
Claude for Writing
Anthropic’s Claude has built a reputation as the writer’s model. Claude Opus 4.5 and the newer Opus 4.6 both perform strongly on writing tasks. Opus 4.6 offers a 200,000-token context window, with 1,000,000 tokens available in beta.
Strengths
Claude produces the most natural-sounding prose among the three major models. Its writing tends to vary sentence length, use unexpected word choices, and avoid the patterns that make AI text obvious. For anyone who needs writing that passes close human inspection, Claude is the strongest choice.
Long-form writing is where Claude truly separates itself. Blog posts, articles, whitepapers, and reports maintain their quality and coherence across thousands of words. This matters because many models start strong and degrade as outputs get longer.
Claude handles longer content better than competitors, especially on projects that span multiple sections or chapters.
Creative writing is Claude’s standout category. Fiction, personal essays, brand narratives, and storytelling come out with a voice that feels more human than what competitors produce. The model handles nuance, subtext, and emotional register better than GPT-5.2 or Gemini.
Claude also excels at adapting to style guides. Give it a writing sample and ask it to match the voice, and it produces closer matches than other models.
Weaknesses
Claude sometimes pushes back on tasks or adds qualifications you did not ask for. A request for straightforward marketing copy might come back with notes about accuracy or suggestions to soften claims. This can slow down workflow for commercial writing.
Formatting compliance is slightly weaker than ChatGPT. When you need rigid structural adherence, like exact word counts, precise heading hierarchies, or specific bullet-point counts, Claude occasionally deviates. It prioritizes making the writing sound good over hitting exact structural targets.
Output speed is also slower than competitors, especially with Opus 4.6. For high-volume writing tasks, this lag adds up.
Gemini for Writing
Google’s Gemini 3.1 Pro is the newest entry at this capability level. Its 1,000,000-token context window and native multimodal features give it unique strengths, though writing quality alone does not match the top two models.
Strengths
Gemini’s biggest advantage for writing is its ability to process extremely large reference materials. You can feed it an entire book, brand guideline document, or research library and ask it to write based on that context. Both Gemini and Claude offer 1M-token windows, but Gemini’s pricing makes large-context writing more affordable at its base rate.
Note that Gemini’s large-context pricing applies a 2x multiplier above 200,000 tokens. Input jumps from $2.00 to $4.00 per million tokens beyond that threshold. Even with this surcharge, processing a 500,000-token reference document remains cheaper than Claude’s flat Opus rate.
Research-heavy writing benefits from Gemini’s integration with Google Search. When writing articles that need current facts, statistics, or citations, Gemini can pull real-time information directly. This saves the manual research step that other models require.
Gemini’s multimodal writing features also make it a strong pick for content that involves images, videos, or other media alongside text. Its native multimodal processing means you can reference visual materials directly in your prompts.
Weaknesses
Gemini’s prose quality trails both ChatGPT and Claude. The writing is competent but tends toward a flat, informational style that reads more like a reference document than engaging content. Creative writing and brand voice work are weaker areas.
All LLMs can produce inaccurate facts in written content, but Gemini shows a stronger tendency to state incorrect details confidently at length. Always fact-check AI-written content before publishing, especially statistics, dates, and named claims.
The model can produce inaccurate details when writing at length. LLM hallucinations are a risk with any model, but Gemini requires more careful review for factual accuracy.
Formatting and tone control are adequate but not as responsive as ChatGPT or Claude. Subtle tone shifts, like moving from “authoritative” to “approachable” mid-piece, are harder to achieve.
Gemini also struggles with iterative editing. When you ask it to revise specific sections, it sometimes rewrites more than requested. It can also lose track of changes you wanted to preserve.
Best LLM for Different Writing Types
The right model depends on what you are writing. This breakdown covers the most common writing categories.
Blog Posts and Articles
Best choice: Claude for quality, ChatGPT for volume.
Claude produces blog content that requires less editing and sounds less AI-generated. If you publish under your own name and care about voice, Claude is the better pick.
ChatGPT is faster and follows structural templates more reliably, making it better for teams producing content at scale. Its instruction following also makes it easier to hit specific word counts and heading formats on the first pass.
Business Emails and Reports
Best choice: ChatGPT.
Professional communication is ChatGPT’s sweet spot. The model’s natural formality, clean structure, and strong instruction following produce emails and reports that need minimal revision. Pair it with email prompts for even better results.
Creative Writing and Fiction
Best choice: Claude.
This is not a close comparison. Claude’s creative output has more voice, more variation, and more emotional depth than either competitor. Writing prompts designed for LLMs can help you get the most from any model, but Claude responds to creative direction better than the alternatives.
Technical Documentation
Best choice: ChatGPT or Claude (close match).
ChatGPT follows documentation templates more precisely. Claude explains complex concepts more clearly for non-technical readers.
Your choice depends on whether the audience is technical or general. For API docs and developer guides, ChatGPT has an edge.
Marketing and Ad Copy
Best choice: ChatGPT.
Short-form persuasive writing, including product descriptions, social media posts, and ad copy, plays to ChatGPT’s strengths. The model is better at being concise and punchy. Claude can match this quality but often needs more specific prompting to keep outputs tight.
Social Media Content
Best choice: ChatGPT for polish, Gemini for trends.
ChatGPT handles character limits and platform-specific formatting well. It produces clean captions and thread structures without much guidance.
Gemini adds value when posts need to reference current events or trending topics, thanks to its search integration. Claude tends to write social content that is too long for platforms that reward brevity.
Long-Form Content (Whitepapers, Guides)
Best choice: Claude.
Anything over 2,000 words favors Claude. The model maintains tone, argument structure, and quality across long outputs better than competitors. Its larger context window with Opus 4.6 also means it can reference more source material while writing.
For whitepapers and in-depth guides, Claude’s ability to sustain a logical argument across sections is a measurable advantage. ChatGPT can produce long content but becomes repetitive after about 1,500 words unless you break the task into smaller chunks.
Pricing for Writing Tasks
Cost matters when writing is a regular part of your work. Here is how the three models compare for typical writing usage as of February 2026.
| Model | Subscription | API Input/1M Tokens | API Output/1M Tokens |
|---|---|---|---|
| ChatGPT (GPT-5.2) | $20/mo (Plus) | $1.75 | $14.00 |
| Claude (Opus 4.6) | $17/mo annual or $20/mo | $5.00 | $25.00 |
| Claude (Sonnet 4.6) | $17/mo annual or $20/mo | $3.00 | $15.00 |
| Gemini (3.1 Pro) | $19.99/mo (Google AI Pro) | $2.00 | $12.00 |
For most writers, the subscription plans tell the real story. The paid tiers cluster around $17-$20/month, though Google also offers a budget Google AI Plus tier at $7.99/month with more limited access. At the subscription level, the cost difference between models is small for casual to moderate use.
OpenAI layers its access across Free, Go ($8/month), Plus ($20/month), and Pro ($200/month) tiers. Anthropic offers a Pro plan at $17/month billed annually ($20/month if paid monthly), with Max tiers at $100 and $200 for heavier usage.
API pricing matters if you are building writing tools or processing high volumes. GPT-5.2 costs $1.75/$14.00 per million tokens, making it mid-range among flagships.
Estimating your actual API costs depends on your monthly volume. A single 2,000-word article uses roughly 3,000-4,000 tokens of output.
For budget-conscious writers, ChatGPT and Gemini both offer capable free tiers. Free vs. paid LLM plans differ mainly in model access and usage limits, not in whether you can write with them.
If you only write occasionally, start with the free tiers of ChatGPT and Claude. Both let you test writing quality before committing to a subscription. Switch to paid plans when you hit usage limits regularly.
Our Recommendation
There is no single best LLM for all writing. But there are clear winners for specific situations.
Choose Claude if you write blog posts, articles, creative content, or anything where voice and naturalness matter. Claude produces the highest-quality prose with the least editing. The gap between ChatGPT and Claude is most visible in creative tasks.
Choose ChatGPT if you need high-volume business writing, rigid format compliance, or marketing copy. ChatGPT follows structural instructions better and produces professional content quickly.
Choose Gemini if your writing relies heavily on research, current data, or multimodal inputs. The Google Search integration and large context window at competitive pricing make it the best choice for research-driven content.
Most professional writers will benefit from access to at least two models. The subscription cost is modest compared to the editing time you save by matching the right model to each task.
These recommendations reflect model capabilities as of February 2026. LLMs improve rapidly. A model that trails today may close the gap with its next release. Revisit your choice every few months.
Conclusion
For most people starting out, the practical answer is to try two models on the same writing task and compare the results. Choosing the right LLM depends on your specific needs, and a 20-minute side-by-side test tells you more than any comparison article can.
Adjusting temperature and other model settings also affects writing output. Lower temperature values produce more predictable, consistent text. Higher values introduce more variety and creativity.
Open-source models like Llama and Mistral offer another path for teams with strict data privacy needs, though they trail the commercial options on writing quality for now.
The best LLM for writing is the one that saves you the most editing time on the content you actually produce. Test with your real tasks, not hypothetical ones. A model that sounds impressive on demo prompts may disappoint on your daily workload.
Frequently Asked Questions

